Думаете, ваш сайт идеально оптимизирован технически? Мой длительный опыт проведения технических аудитов с вами не согласится. За более чем шесть лет ко мне на анализ ни разу не попадал сайт без технических ошибок, даже если это был аудит работы стороннего агентства или специалиста. На средних и крупных проектах, даже при регулярном полном аудите сайта, практически невозможно уследить за полным техническим здоровьем ресурса в бесконечной череде изменений и улучшений, вносимых на сайт.
В этом блоке собраны самые распространенные ошибки, которые встречаются на 90% всех проверяемых сайтов. Они легко диагностируются и исправляются. Советую вам их проверить в первую очередь, поскольку вероятность их обнаружения на вашем сайте очень велика.
При запуске нового сайта важно определить главное зеркало. Существует 4 варианта:
| http://site.com/ | http://www.site.com/ | https://site.com/ | https:/www.site.com/ |
*в очень редких случаях сайт отображается по 5-му варианту, URL с IP адресом вида: xxx.xxx.xx.xx:xx или site.com:xx.
Поисковые системы считают эти версии разными сайтами и будут воспринимать их как полные дубликаты с попыткой поискового спама.
Реже встречается случай, когда зеркала склеены, но это реализовано через 302 редирект (302 Moved Temporarily), что в отличие от 301 редиректа (301 Moved Permanently), сообщает поисковому роботу о временном, а не постоянном перемещении страницы на новый адрес, из-за чего он может не проиндексировать конечный URL редиректа и оставить в индексе начальный URL.
Как должно быть: Со всех возможных версий сайта настроен 301 редирект (301 Moved Permanently) на основную версию, чтобы избежать полных дубликатов ресурса.
Существует множество возможных видов генерируемых дублей страниц различными CMS сайтов. Ниже приведены самые распространенные примеры ошибок:
| Вид редиректа | Возможный дубль | Возможный оригинал |
| Обработка / в конце URL | https://site.com/category | https://site.com/category/ |
| Лишние / в структуре URL | https://site.com/category//https://site.com///category | https://site.com/category/ |
| Верхний регистр URL | https://site.com/CaTEgory/ | https://site.com/category/ |
| Индексные копии файлов | https://site.com/index.phphttps://site.com/index.html | https://site.com/ |
| Индексные копии хостинга | https://site.com/index.htm | https://site.com/ |
Если не настроить 301 редиректы с других версий страниц, они создадут полные или частичные копии друг друга, которые поисковые роботы воспринимают как спам и дублированный контент, что в итоге мешает нормальному ранжированию основной версии.
Как должно быть: Версия страницы сайта должна находится только по одному URL адресу. Поисковые системы считают любое изменение в URL совершенно другой страницей, которая дубликат полезной продвигаемой страницы.
Многие специалисты закрывают страницы от индексации через файл robots.txt, который является только рекомендацией к сканированию, а не ультиматумом.
Как должно быть: Все нежелательные для попадания в индекс страницы закрыты через <meta name=»robots» content=»noindex, follow» />. Значение dofollow или nofollow прописывается в зависимости от содержания страниц.
Распространена ошибка добавления некорректных рекомендаций к сканированию поисковым роботам в файл robots.txt не индексировать все страницы сайта, содержащие get-параметры, правилом Disallow: /*? в разных его вариациях, или закрывают системные папки типа Disallow: /wp-content/. некоторых CMS есть рекомендации по добавлению базового файла robots.txt с такой ошибкой.
При добавлении никто не учитывает, что задевает этими правилами ссылки на медиафайлы, скрипты и стили, например:
*.css?ver=45 или
*/wp-content/plugins/*jquery.modal.min.css

Даже учитывая рекомендательный характер файла, GoogleBot в последующем не всегда может корректно обработать и воспринять страницу из-за ошибок сканирования отдельных элементов.
Как должно быть: Чтобы избежать дублирования контента на сайтах, где много ненужных страниц с гет-параметрами, и не навредить рендерингу страниц поисковыми роботами, используются правила указания канонических страниц с помощью <link rel=»canonical» href=»[url]» /> для всех страниц содержащих get-параметры, кроме страниц пагинации (если они реализованы в виде ?page=n, а не /page-n/).
На сайте генерируют sitemap.xml и не устанавливают для него правила добавления новых ссылок и цикл автообновления. Таким образом в файл попадают ссылки с кодами ответа сервера 30Х, 40Х, закрытые к индексации в noindex или неканонические страницы, что мешает роботам поисковых система корректно обработать файл и расходует лишний краулинговый бюджет на переобход ненужных страниц.
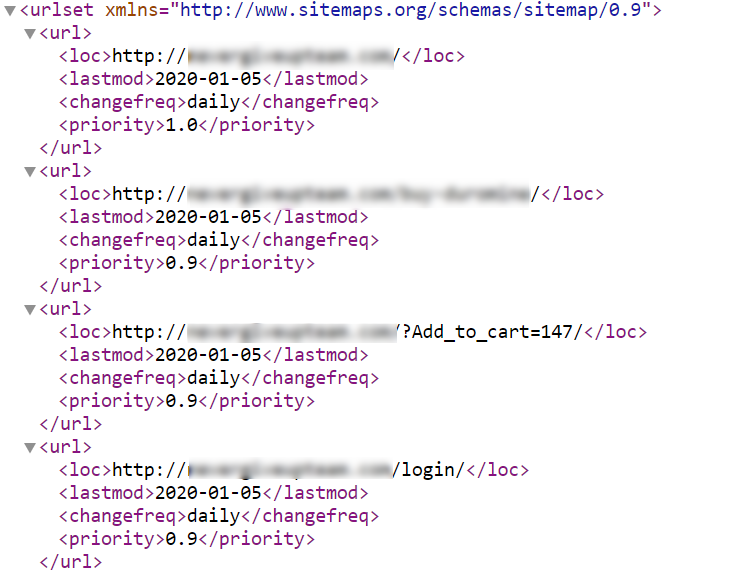
Как должно быть: Файл содержит только ссылки открытые для индексации и с кодом ответа 200 OK. При добавлении новых URL доступных к индексации они автоматически попадают в карту сайта. Файл самообновляется в заданный настройками период, зависящий от типа и величины сайта.
С оптимизацией страницы 404 ошибки связано несколько проблем, и все они встречаются в равной степени часто.
Несуществующие страницы с кодом ответа 200 OK. Из-за отсутствия корректной настройки не все несуществующие страницы отдают код ответа сервера 404 Not Found. Это приводит к индексированию несуществующих страниц, которые могут генерироваться внутри сайта или с внешних ссылок, содержащих ошибки, что приводит к их попаданию в индекс поисковых систем и созданию частичных дублей продвигаемых страниц.
Чаще всего эта ошибка встречается в CMS Bitrix на страницах 3+ уровня вложенности и на страница блога.
Не настроено оформление страницы 404 ошибки. При попадании на несуществующую страницу пользователь видит белый экран без информации и каких-либо ссылок, позволяющих ему вернуться на сайт.

Перенаправление при запросе несуществующей страницы. При запросе несуществующей страницы происходит 301 или 302 редирект (что еще хуже) на статическую страницу 404 ошибки, которая обычно имеет примерно такой вид:
/404-page.html. В лучшем случае, эта страница отдает корректный код ответа, но зачастую это индексируемая страница с 200 кодом ответа сервера.
Как должно быть: Все несуществующие страницы сайта отдают код ответа 404 Not Found и отображают шаблон страницы 404 ошибки, который оформлен в шаблоне дизайна сайта, содержит дополнительную информацию и пути выхода со страницы.
Всегда присутствует как минимум одна из нижеперечисленных ошибок.
Указание канонической страницы. Чаще всего каноническая страница просто не определена. Реже указание канонической страницы задано неверно, что аналогично приводит к дублированию.
Дублирование текста на страницах. Текст разводящей страницы копируется на всех последующих страницах пагинации.
Дубль основной страницы. Присутствует полный дубликат основной страницы пагинации, чаще всего доступные по адресу: ?page=1 и т.п.
Не задан шаблон генерации мета. Все мета-теги и заголовки страниц пагинации дублируют друг друга.
Все перечисленные выше ошибки ведут к дублированию контента и ухудшению ранжирования затронутых страниц.
Как должно быть: На страницах пагинации указан корректно указанный <link rel=»canonical» href=»[url]» />. Текст основной страницы пагинации не дублируется на последующих страницах. У основной страницы нет дубликата в виде первой страницы.
Во многих CMS, мета-теги Description и теги Title, H1, по умолчанию не прописываются. На некоторых движках максимум в Title подтягивается значение H1, что тоже провоцирует дублирование, которое приводит к ухудшению ранжирования страницы.

Если теги описания отсутствуют, то Google самостоятельно формирует сниппет сайта в поисковой выдаче, который скорее всего будет неинформативным, что снижает показатель кликабельности по ссылкам сайта для перехода.
Как должно быть: В идеальном варианте вся информация прописывается вручную с соблюдением простых рекомендаций. В быстром варианте задается шаблон генерации для каждого типа страниц.
Сайт содержит большое количество внутренних перенаправлений или битых ссылок. Это происходит при частой смене внутренних URL страниц без настроенной на движке автозамены в коде сайта. Также происходит при проставлении ручной перелинковки, про которую потом все забывают и на которую не действуют правила автозамены.
Большое количество внутренних ошибок сайта приводит к ухудшению сканирования ресурса из-за бесполезной растраты краулингового бюджета поискового робота и в отдельных случаях к ухудшению поведенческих факторов.
Как должно быть: Несуществующие страницы заменены на альтернативу, просто удалены из кода или удалены и перенаправлены на релевантные страницы, в зависимости от конкретного случая. Страницы с перенаправлениями заменены на свой конечный путь. Служебные страницы с перенаправлениями закрыты от индексации.
Не самые частые ошибки, но тоже встречаются и мешают нормальному ранжированию ресурса. Чаще всего такие ошибки появляются на определенных типах ресурса, из-за чего встречаются не на каждом сайте.
Есть несколько видов ссылок, которые нужны для удобства пользователя и выполняют только техническую роль, но бесполезны с точки зрения продвижения:
Совершая переходы по таким ссылкам, поисковый робот тратит свой краулинговый бюджет на их сканирование, что может привести к проблемам со скоростью индексирования ресурса.
Как должно быть: Желательно такие ссылки не просто закрывать от индексации или каноникализировать, а вообще вырезать из кода сайта.
Часто при переносе сайта на другое зеркало или адрес все сквозные настройки оставляют без изменений. Самые распространенные примеры – покупка SSL сертификата и смена протокола с http на https или добавление/удаление www. префикса по чьим-то фантазиям, что так будет лучше.
В этих случаях самыми распространенными не перенесенными настройками кода могут быть:
Это приводит к полному краху всех настроек по устранению дублей страниц или указанию на некорректные источники, созданию множества ошибок внутренних страниц сайта.
Как должно быть: При переносе сайта или смене главного зеркала абсолютно вся информация и все технические настройки сайта обязательно сохраняются и переносятся по мере необходимости, в зависимости от проекта и вида переноса. Переезд сайта отдельная большая тема, по которому составляется огромное техническое задание, чтобы максимально сохранить накопленный результат.
Иногда склейку зеркал или дублей технически бесполезных страниц делают через указание атрибута rel=»canonical» вместо настройки 301 Moved Permanently. Даже если вручную задана каноническая страница, поисковый робот Google может спокойно выбрать другую страницу, поскольку воспринимает атрибут как рекомендацию. В случае настройки 301 Moved Permanently у него не останется выбора.
Как должно быть:
Все технически бесполезные дубликаты страниц сайта склеены через 301 редирект. Исключение составляют ЧПУ ссылки с get-параметрами и служебные страницы.
При определении языковых версий через <link rel=»alternate»/> допускают типичные ошибки:
<link rel=»alternate» hreflang=»en-us» href=»https://site.md/en/» />
<link rel=»alternate» hreflang=»ro-ro» href=»https://site.md/ro/» />
<link rel=»alternate» hreflang=»ru-ru» href=»https://site.md/ru/» />
Как должно быть:
Все ссылки в атрибуте абсолютные, без get параметров и отдают код ответа сервера 200 ОК. Указаны ссылки на все альтернативные языковые/региональные версии страницы, включая самореферентный URL (сам на себя).
Довольно часто при разработке сайта создают dev. версию на отдельном сайте или поддомене и не закрывают ее от индексации поисковыми системами (должно заставить задуматься о компетенции разработчиков).

В итоге сайт в разработке уже индексируется. Если его полностью скопировали с оригинала, то он уже полностью дублирует весь контент текущего сайта, понижая его ранжирование. Новый контент на разрабатываемом сайте уже проиндексировался в поисковой системе и его расхватали сервисы, копирующие контент, что в последующем сделает его не уникальным на основном сайте.
Как должно быть: Все служебные версии сайта закрыты от индексации. Минимум – noindex. В идеальном варианте – закрытие на http доступ через htaccess.
Не один раз видел, как теги с атрибутами canonical, noindex, alternate и прочие, добавлены в <body>, а не <head> секции сайта.
Как должно быть: Добавляйте все теги и атрибуты в соответствии с рекомендациями в справке Google, чтобы поисковые роботы смогли их учитывать и корректно обработать.
Сайт может прекрасно функционировать, все страницы будут отображаться и работать, но в выдачу будут попадать тонны сгенерированных страниц со странными символами, ведущие на сторонние сайты. После этого постепенно начнут меняться мета-теги текущих страниц в выдаче и в финале, клики по основным ссылкам сайта в поисковой выдаче тоже будут вести на сторонний сайт через клоакинг.
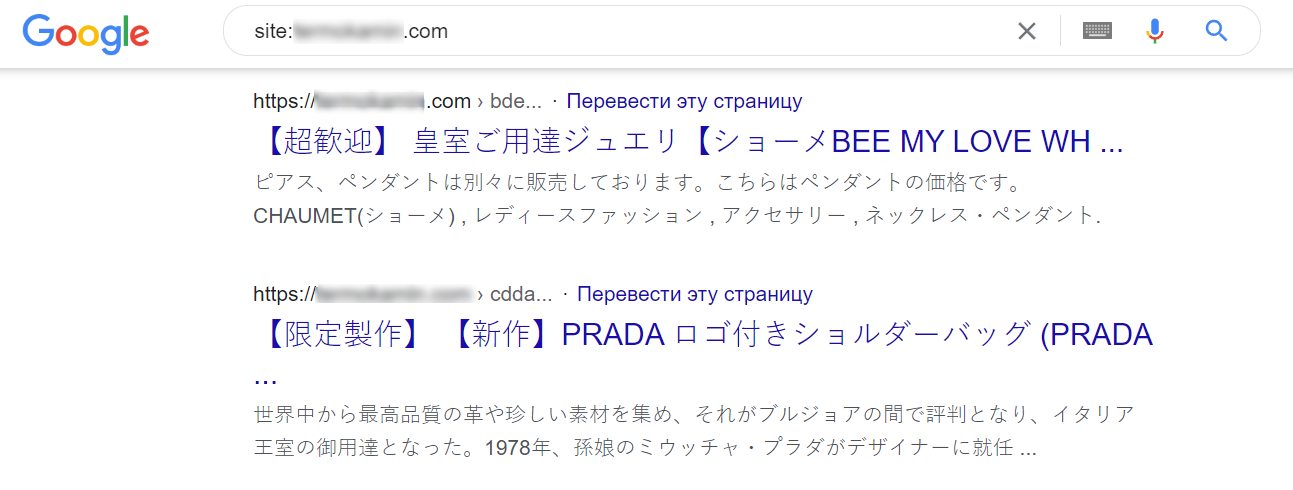
Обычно это происходит в следующих случаях:
После чистки всего мусора и возврата старых настроек сайт обычно восстанавливается в течение 1-2-х месяцев.
Как должно быть: Покупайте и устанавливайте только проверенные и популярные шаблоны дизайна и плагины на свой сайт. Своевременно скачивайте и устанавливайте обновления компонентов. Периодически меняйте доступы к сайту, особенно после работы стороннего подрядчика.
Из рубрики профессиональных болей. Если вы специалист и читаете это, пожалуйста, не делайте так 🙂
Многие агентства или специалисты зачем-то указывают абсолютно идентичные правила в robots.txt для нескольких User-Agent: * поисковых роботов, делая тем самым бесполезное дублирование кода. При таком варианте приходится объяснять клиенту, почему это бесполезно, либо добавлять новое правило для всех перечисленных ботов.

Самое жуткое, что приходилось видеть на практике – указание для 5-ти разных User-Agent: Общий, Google, Yandex, Rambler, Bing, одних и тех же правил, при этом в одном из правил была допущена ошибка, которую скопировали на всех остальных ботов.
Регулярно мониторить техническое состояние сайта необходимо на всех типах проектов разной величины, которые регулярно изменяются. Даже на наших личных проектах периодически всплывают разные виды ошибок, которые без проведения целенаправленной проверки обнаружить невозможно, поэтому, кроме постоянного мониторинга, мы проводим регулярные технические аудиты всех внутренних и клиентских проектов.
Для тех, кто дочитал до конца, случай из жизни: буквально пару недель назад при внедрении доработки по приведению URL языковых версий в единый вид сгенерировалось по два дубля для каждой продвигаемой страницы сайта, что привело к потере трафика. Без должного SEO-сопровождения сайта такую ошибку можно и не заметить или просто не знать о её существовании, что мешает реализовать весь потенциал сайта.
