Considerați că site-ul dvs. este optimizat ideal din punct de vedere tehnic? Experiența mea îndelungată în efectuarea de audituri tehnice îmi permite să nu fiu de acord cu dumneavoastră. De mai bine de șase ani niciodată nu am analizat un site fără erori tehnice, chiar dacă a fost un audit al lucrului făcut de către o agenție terță sau de către un specialist. În cazul proiectelor medii și mari, chiar și cu un audit complet regulat al site-ului, este aproape imposibil să urmăriți starea tehnică completă a acestuia, în special reieșind din fluxul nesfârșit de modificări și îmbunătățiri ale site-ului.
Acest bloc conține cele mai frecvente erori care apar pe 90% din toate site-urile verificate. Acestea sunt ușor de diagnosticat și fixat. Recomandarea mea este să le verificați în primul rând, deoarece probabilitatea ca acestea să se regăsească și pe site-ul dvs. este foarte mare.
Când lansați un nou site, este important să identificați oglinda principală. Există 4 opțiuni:
| http://site.com/ | http://www.site.com/ | https://site.com/ | https:/www.site.com/ |
*în cazuri foarte rare, site-ul este afișat prin a 5-a opțiune, o adresă URL cu o adresă IP ca: xxx.xxx.xx.xx:xx или site.com:xx.
Motoarele de căutare consideră că aceste versiuni reprezintă site-uri diferite și le vor trata ca duplicate complete cu tentativă de spam.
Mai rar întâlnit este cazul când oglinzile sunt îmbinate, acest lucru fiind implementat prin redirecționări 302 (302 Moved Temporarily), care, spre deosebire de redirecționările 301 (301 Moved Permanently, informează robotul de căutare despre relocarea temporară și nu permanentă a paginii la o nouă adresă, din cauza căreia este posibil să nu indexeze adresa URL de final a redirecționării și să lase în index adresa URL de inițială.
Cum ar trebui să fie: Din toate versiunile posibile ale site-ului, redirecționările 301 (301 Moved Permanently) sunt setate către versiunea principală pentru a evita duplicarea completă a resursei.
Există multe tipuri posibile de duplicate ale paginilor generate de diverse CMS ale site-urilor. Mai jos sunt cele mai frecvente exemple de erori:
| Tip de redirecționare | Dublu posibil | Original posibil |
| Prelucrare / la sfârșitul URL-ului | https://site.com/category | https://site.com/category/ |
| Extra / în structura URL | https://site.com/category//https://site.com///category | https://site.com/category/ |
| Adresa URL cu majuscule | https://site.com/CaTEgory/ | https://site.com/category/ |
| Copiile indexate ale fișierelor | https://site.com/index.phphttps://site.com/index.html | https://site.com/ |
| Copii indexate ale hostingului | https://site.com/index.htm | https://site.com/ |
Dacă nu configurați redirecționările 301 din alte versiuni de pagini, acestea vor crea copii complete sau parțiale una ale celeilalte, pe care roboții de căutare le percep drept spam și conținut duplicat, ceea ce interferează în cele din urmă cu poziționarea normală a versiunii principale.
Cum ar trebui să fie: versiunea paginii ar trebui să fie localizată la o singură adresă URL. Motoarele de căutare consideră că orice modificare a adresei URL este o pagină complet diferită, care este o copie a unei pagini promovate.
Mulți specialiști închid paginile de la indexare prin fișierul robots.txt, acesta fiind doar o recomandare pentru crawling, și nu un ultimatum.
Cum ar trebui să fie: toate paginile nedorite sunt închise prin <meta name=”robots” content=”noindex, follow” /> . Valoarea dofollow sau nofollow este specificată în funcție de conținutul paginilor.
O greșeală larg răspândită ține de adăugarea recomandărilor incorecte pentru accesarea cu crawlere de către roboții de căutare în fișierul robots.txt, conform cărora nu se vor indexa toate paginile site-ului care conțin get-parametrii, prin intermediul Disallow: /*? în diversele lui variante sau închiderea folderelor de sistem precum Disallow: /wp-content/. Unele CMS au recomandări legate de adăugarea unui fișier robots.txt de bază cu această eroare.
În timpul adăugării nu se ia în considerare faptul că aceste reguli afectează linkurile către fișiere media, scripturi și stiluri, de exemplu:
*.css?ver=45 sau
*/wp-content/plugins/*jquery.modal.min.css

Chiar dacă are în vedere și natura consultativă a fișierului, GoogleBot nu de fiecare dată poate procesa și percepe pagina corect din cauza erorilor de scanare a elementelor individuale.
Cum ar trebui să fie: pentru a evita duplicarea conținutului pe site-urile unde există o mulțime de pagini inutile cu parametri get și pentru a nu afecta redarea paginilor de către roboții de căutare, sunt utilizate regulile pentru specificarea paginilor canonice folosind <link rel=”canonical” href=”[url]” / > pentru toate paginile care conțin parametri get, cu excepția paginilor de paginare (dacă sunt implementate ca ?page=n, nu și /page-n/).
Site-ul generează un sitemap.xml și nu stabilește reguli pentru adăugarea de noi linkuri, precum nu stabilește și ciclu de actualizare automată. Astfel, în fișier sunt incluse linkurile cu codurile de răspuns ale serverului 30X, 40X, închise pentru indexare în noindex sau paginile non-canonice, ceea ce împiedică roboții motoarelor de căutare să proceseze corect fișierul și solicită buget suplimentar de accesarea cu crawlere pentru a parcurge din nou paginile inutile.
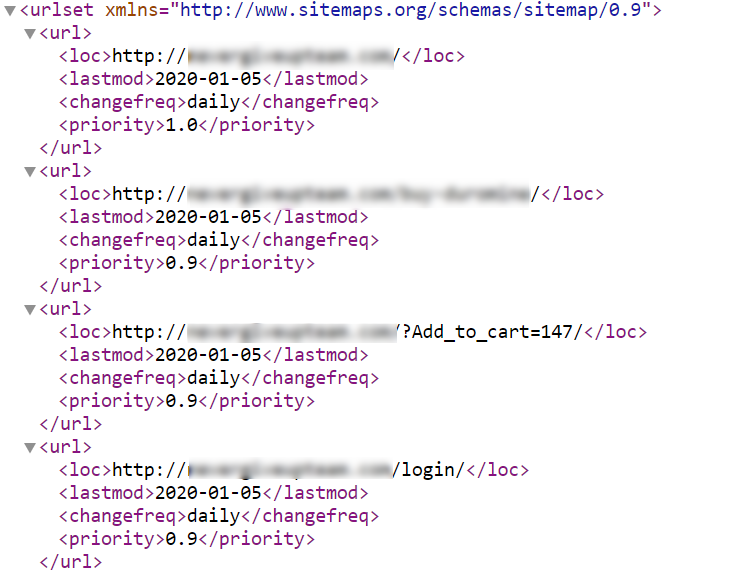
Cum ar trebui să fie: fișierul conține doar linkuri deschise pentru indexare și cu un cod de răspuns de 200 OK. La adăugarea noilor adrese URL disponibile pentru indexare, acestea sunt incluse automat în harta site-ului. Fișierul se actualizează automat în perioada specificată de setări, în funcție de tipul și dimensiunea site-ului.
Există mai multe probleme asociate cu optimizarea unei pagini de eroare 404 și toate sunt la fel de frecvente.
Pagini inexistente cu un cod de răspuns de 200 OK. Din cauza lipsei unei configurații adecvate, nu toate paginile inexistente returnează un cod de răspuns de server 404 Not Found . Acest lucru duce la indexarea paginilor inexistente, care pot fi generate în cadrul site-ului sau din link-uri externe care conțin erori, ceea ce duce la includerea acestora în indexul motorului de căutare și la crearea de duplicate parțiale ale paginilor promovate.
Cel mai des, această eroare apare în CMS Bitrix pe paginile de nivele de imbricare 3+ și pe pagina de blog.
Designul paginii de eroare 404 nu este configurat. Când ajunge pe o pagină inexistentă, utilizatorul vede un ecran alb fără informații și fără link-uri care îi permit să revină pe site.

Redirecționare în cazul solicitării unei pagini inexistente. Solicitarea unei pagini inexistente are ca rezultat o redirecționare 301 sau 302 (ceea ce este și mai rău) către o pagină de eroare statică 404, care de obicei arată cam așa:
/404-page.html. În cel mai bun caz, această pagină returnează un cod de răspuns valid, dar cel mai des este o pagină indexată cu codul de răspuns de server 200.
Cum ar trebui să fie: Toate paginile inexistente ale site-ului returnează un cod de răspuns 404 Not Found și afișează un șablon de pagină de eroare 404, care este stilat în șablonul de design al site-ului, conține informații suplimentare și modalități de a părăsi pagina.
Cel puțin una dintre următoarele erori este prezentă practic întotdeauna.
Specificarea paginilor canonice. De cele mai multe ori, pagina canonică pur și simplu nu este definită. Mai rar, specificația canonică a paginii este setată incorect, ceea ce duce în mod similar la duplicare.
Text duplicat pe pagini. Textul paginii de destinație este copiat pe toate paginile de paginare ulterioare.
Duplicat al paginii principale. Există un duplicat complet al paginii principale de paginare, cel mai adesea disponibil la: ?page=1, etc.
Șablonul de meta generare nu este setat. Toate meta tagurile și titlurile paginilor de paginare se dublează reciproc.
Toate erorile de mai sus duc la conținut duplicat și la o clasare slabă a paginilor afectate.
Cum ar trebui să fie: Pe paginile de paginare trebuie să fie specificat corect < link rel = „canonic” href = „[url]” / > . Textul paginii principale de paginare nu este duplicat pe paginile următoare. Pagina principală nu are ca duplicat prima pagină.
În destul de multe CMS, meta-description și meta-title, precum și etichetele H1 nu sunt scrise implicit. Pe unele motoare, maximul din Titlu este tras în sus de valoarea H1, ceea ce, la fel, provoacă duplicarea și duce la înrăutățirea poziționării paginii.

Dacă nu există etichete de descriere, atunci Google generează în mod independent un fragment al site-ului în rezultatele căutării care, cel mai probabil, nu va fi informativ, ceea ce reduce rata de click pe link-urile site-ului.
Cum ar trebui să fie: în mod ideal, toate informațiile sunt scrise manual, urmând instrucțiuni simple. În versiunea rapidă, este setat un șablon de generare pentru fiecare tip de pagină.
Site-ul conține un număr mare de redirecționări interne sau link-uri fracturate. Acest lucru se întâmplă atunci când adresele URL interne ale paginilor sunt modificate frecvent fără corecția automată în codul site-ului, configurată pe motorul site-ul. De asemenea, se întâmplă în cazul linkingului manual, de care toată lumea uită apoi și care nu se supune regulilor de corectare automată.
Un număr mare de erori interne ale site-ului duce la o înrăutățire a scanării resurselor din cauza risipei inutile a bugetului de crawling al robotului de căutare și, în unele cazuri, la o înrăutățire a factorilor comportamentali.
Cum ar trebui să fie: Paginile inexistente sunt înlocuite cu alternative, fiind pur și simplu eliminate din cod sau eliminate și redirecționate către paginile relevante, după caz. Paginile cu redirecționări au fost înlocuite prin linkul său final. Paginile de tip service, cu redirecționări, sunt închise de la indexare.
Acestea nu sunt cele mai frecvente erori, dar ele apar și interferează cu poziționarea normală a site-ului. Cel mai des, astfel de erori apar pe anumite tipuri de resurse, motiv pentru care nu se regăsesc pe fiecare site.
Există mai multe tipuri de linkuri care asigură comoditatea utilizatorului și îndeplinesc doar un rol tehnic, dar sunt inutile în ceea ce privește promovarea:
Navigând pe astfel de link-uri, robotul de căutare își cheltuie bugetul de crawling pentru a le scana, ceea ce poate duce la probleme cu viteza de indexare a resurselor.
Cum ar trebui să fie: este de dorit nu numai să închideți astfel de legături de la indexare sau canonizare, ci și să le eliminați complet din codul site-ului.
Adesea, atunci când transferați un site către o altă oglindă sau adresă, toate setările end-to-end sunt lăsate neschimbate. Cele mai comune exemple țin cumpărarea unui certificat SSL și schimbarea protocolului http pe https sau adăugarea/eliminarea prefixului www. în baza fanteziei cuiva, precum că așa ar fi mai bine.
În aceste cazuri, cele mai frecvente modificări de cod neportate țin de:
Acest lucru duce la o prăbușire completă a tuturor setărilor orientate spre eliminarea paginilor duplicate sau indicarea surselor incorecte, creând multiple erori pe paginile interne ale site-ului.
Cum ar trebui să fie: La transferul unui site sau la schimbarea oglinzii principale, absolut toate informațiile și toate setările tehnice ale site-ului sunt în mod obligatoriu salvate și transferate în măsura necesităților, în funcție de proiect și tipul de transfer. Mutarea site-ului reprezintă o mare sarcină separată, pentru realizarea căreia care este compilată o sarcină tehnică uriașă, cu scopul de a păstra cât mai mult din rezultatul deja cumulat.
Uneori îmbinarea oglinzilor sau a duplicatelor paginilor inutile din punct de vedere tehnic se face prin specificarea atributului rel = „canonic” în loc de a seta 301 Moved Permanently . Chiar dacă pagina canonică este setată manual, crawlerul Google poate selecta în siguranță o altă pagină, deoarece percepe atributul ca pe o recomandare. În cazul setării 301 Moved Permanently, crawler-ul nu va avea de ales.
Cum ar trebui să fie:
Toate duplicatele inutile din punct de vedere tehnic ale site-ului sunt îmbinate prin redirecționări 301. Excepțiile reprezintă legăturile NC cu parametrii-get și paginile de tip service.
La definirea versiunilor de limbă prin se comit următoarele erori răspândite:
<link rel=”alternate” hreflang=”en-us” href=”https://site.md/en/” />
<link rel=”alternate” hreflang=”ro-ro” href=”https://site.md/ro/” />
<link rel=”alternate” hreflang=”ru-ru” href=”https://site.md/ru/” />
Cum ar trebui să fie:
Toate referințele din atribut sunt absolute, fără parametri get și returnează un cod de răspuns de server 200 OK. Sunt furnizate link-uri către toate versiunile alternative ale paginii în limbă/regiune, inclusiv adresa URL de auto-referință (către sine însăși).
Destul de des, atunci când dezvoltă un site, se creează o versiune dev. sau un subdomeniu separat, care nu este închis de la indexarea de către motoarele de căutare (în acest caz ar trebui să vă puneți întrebări legate de competența dezvoltatorilor).

Ca urmare, site-ul în curs de dezvoltare este deja indexat. Dacă a fost creat prin copierea completă din original, atunci se dublează complet tot conținutul site-ului curent, scăzând poziționarea acestuia. Noul conținut de pe site-ul în curs de dezvoltare a fost deja indexat în motorul de căutare și a fost captat de serviciile care copiază conținutul, ceea ce nu îi va mai permite să fie unic în viitor.
Cum ar trebui să fie: Toate versiunile de service ale site-ului sunt închise de la indexare. Cel puțin va fi utilizat noindex. În mod ideal, se va închide accesul http prin htaccess.
Am văzut de mai multe ori cum etichetele cu atribute canonical, noindex, alternate și altele au fost adăugate în , și nu în secțiunea a site-ului.
Cum ar trebui să fie: adăugați toate etichetele și atributele conform recomandărilor din Suport Google, astfel încât roboții de căutare să le poată lua în considerare și să le proceseze corect.
Site-ul poate funcționa perfect, toate paginile se vor afișa și vor funcționa corect, dar vor exista tone de pagini generate cu caractere ciudate, care vor duce către site-uri terțe. După aceasta, treptat se vor modifica și meta tagurile paginilor curente din rezultatele căutării, iar într-un final, treptat și link-urile site-ului principal din rezultatele căutării vor duce, prin cloaking, de asemenea, la un site terț.
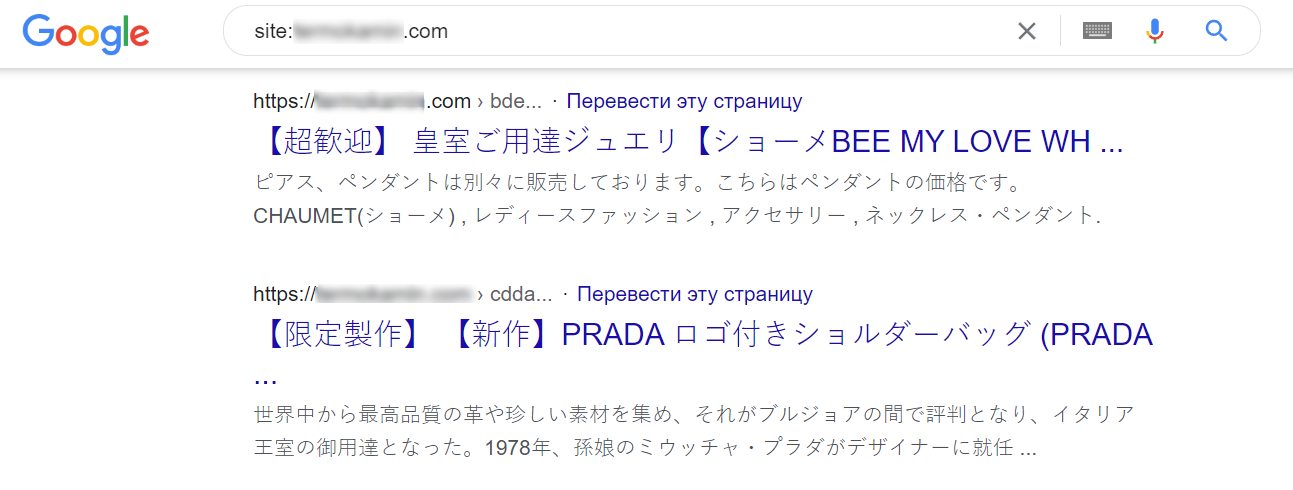
Acest lucru se întâmplă de obicei în următoarele cazuri:
După eliminarea gunoiului și revenirea la setările vechi, site-ul este restaurat, de obicei, în 1-2 luni.
Cum ar trebui să fie: cumpărați și instalați numai șabloane și plugin-uri de pe site-ul dvs. design populare și de încredere. Descărcați și instalați actualizările componentelor în timp util. Modificați periodic drepturile de acces la site, mai ales după lucrările efectuate de către cineva terț.
Din categoria durerilor profesionale. Dacă sunteți expert în domeniu și citești asta, vă rog să nu comiteți erorile descrise mai jos 🙂
Din anumite motive, multe agenții sau specialiști specifică reguli absolut identice în robots.txt pentru mai mulți roboți de căutare User-Agent:*, făcând astfel duplicarea codului absolut inutilă. În acest caz, este nevoie de explicat clientului de ce acest lucru este inutil sau să adăugați o nouă regulă pentru toți roboții listați.

Cel mai groaznic lucru pe care l-am văzut în practică este o regulă absolut identică pentru 5 User Agents diferiți: General, Google, Yandex, Rambler, Bing, iar în în regulă a fost comisă o eroare, care ulterior a fost copiată și în cazul celorlalți roboți.
Indiferent de tipul și dimensiunea proiectului, este necesar să se monitorizeze în mod regulat starea tehnică a site-ului. Chiar și în proiectele noastre personale apar periodic diverse tipuri de erori, care nu pot fi detectate fără o verificare țintită. Așadar, pe lângă monitorizarea constantă, efectuăm audituri tehnice regulate ale tuturor proiectelor interne și ale proiectelor clienților noștri.
Pentru cei care au ajuns până aici, un caz din viață: în urmă cu doar câteva săptămâni, la implementarea unei îmbunătățiri pentru a aduce URL-ul versiunilor lingvistice la o singură formă, au fost generate două duplicate pentru fiecare pagină promovată a site-ului, ceea ce a generat pierderea traficului. Fără un suport SEO adecvat al site-ului, este posibil ca o astfel de eroare să nu fie observată sau pur și simplu să nu fie conștientizată existența acesteia, ceea ce nu permite site-ului să-și atingă potențialul maxim.
